聚類分析是無監(jiān)督學習��,即我們事先不知道正確結果��,數(shù)據(jù)沒有附帶標簽��,需要通過某些算法來發(fā)現(xiàn)數(shù)據(jù)內在的本質和規(guī)律��,從而實現(xiàn)對數(shù)據(jù)內在關聯(lián)結構的分類。聚類分析就是根據(jù)樣本間的相似性對樣本集進行分組��,使得組內差距最小化��,組間差距最大化。如:客戶細分��、用戶畫像��、新聞聚類��、基因分類等��。為數(shù)據(jù)挖掘和業(yè)務分析提供了有力支持��。
聚類分析流程步驟如下:
第一步接入數(shù)據(jù):聚類算法要求接入結構化數(shù)據(jù)��,自變量數(shù)據(jù)類型為數(shù)值型或字符型,不支持日期型和文本型��。若接入的自變量數(shù)據(jù)不滿足聚類分析的數(shù)據(jù)要求��,可以通過屬性變化節(jié)點進行數(shù)據(jù)類型轉換或重新接入數(shù)據(jù)��。
第二步設置角色:通過設置角色節(jié)點確定聚類分析研究的屬性列��,設置為自變量��。聚類算法必須設置自變量��,不支持設置因變量��,自變量可以是連續(xù)型(數(shù)值)也可以是離散型(字符)��。當然在設置角色節(jié)點之前也可以根據(jù)實際業(yè)務和數(shù)據(jù)情況進行原始數(shù)據(jù)的清洗��、集成、轉換��、離散��、歸約��、特征選擇和提取等一系列預處理工作��,達到挖掘建模的數(shù)據(jù)標準。
第三步建立模型:根據(jù)分析方案和處理后的業(yè)務數(shù)據(jù)構建聚類模型��,平臺內置9種聚類算法可以直接拖拽使用,并配置對應的模型參數(shù)��,包括:KMeans��、模糊C均值、EM聚類��、Hierarchy��、Kohonen聚類��、視覺聚類��、Canopy��、冪迭代和兩步聚類。當我們不清楚當前數(shù)據(jù)更適合哪種聚類算法��,或不清楚多個模型中哪個模型效果更好時��,我們有兩種處理方案:方案一��,通過多分支節(jié)點將相同的輸入數(shù)據(jù)同時傳遞給多個不同的聚類模型��,由平臺推薦出多個模型中的最優(yōu)模型��;第二種��,通過自動聚類節(jié)點選擇多個聚類算法一次性構建模型��,該節(jié)點內嵌自動擇參功能��,將多個算法及其對應的多組參數(shù)生成的多種模型進行評估比較��,最終幫助我們推薦出最佳算法及相應的最佳參數(shù)組合��。
第四步模型評估:利用聚類評估節(jié)點檢驗聚類模型的可靠性,在洞察中根據(jù)一些評價的指標(如總離差平方和等)或者圖表展示��,獲得質量最佳的聚類模型��。
完成上述建模之后執(zhí)行流程��,流程執(zhí)行成功后自動跳轉至洞察頁面��,在洞察頁面點擊可以查看模型的分析結果��,我們通過示例流程來詳細介紹��。點擊【KMeans】查看聚類結果��,在聚類圖中以看到各類別的樣本數(shù)��,聚類1樣本數(shù)39個��,聚類2樣本數(shù)50個��,聚類3樣本數(shù)61個��,如下圖所示:
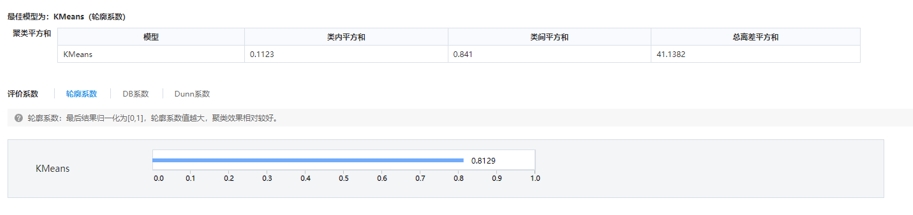
點擊【聚類評估】查看模型的評估結果��,如下圖:
總離差平方和��,值越小說明真實數(shù)值與期望值之間相差越小��,可被用來評估模型的準確率��。輪廓系數(shù)��、DB系數(shù)��、Dunn系數(shù)��,3個系數(shù)均是值越大聚類效果越好��。我們從聚類評估結果可以看出��,KMeans算法的總離差平方和都比較小��,輪廓系數(shù)值都在0.8以上��,模型聚類效果較好��。
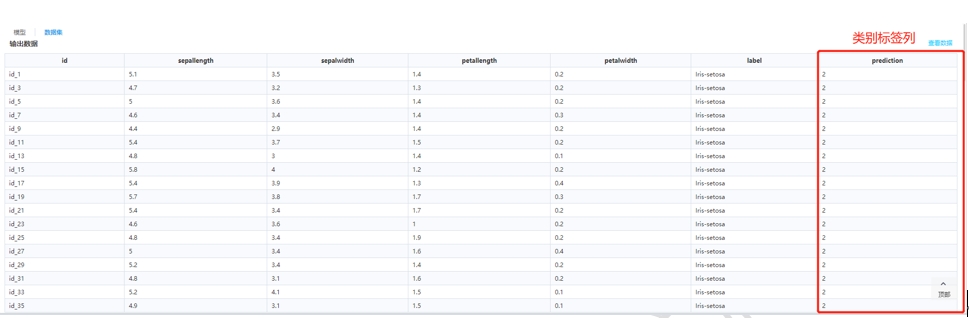
再來看數(shù)據(jù)集的情況,可以看到最后一列屬性“prediction”為類別標簽列��。































據(jù)治理遇上智能體:AI浪潮下的數(shù)據(jù)治理變革之路")




 Tempo商業(yè)智能平臺
Tempo商業(yè)智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數(shù)據(jù)工廠平臺
Tempo數(shù)據(jù)工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數(shù)據(jù)治理平臺
Tempo數(shù)據(jù)治理平臺 Tempo主數(shù)據(jù)管理平臺
Tempo主數(shù)據(jù)管理平臺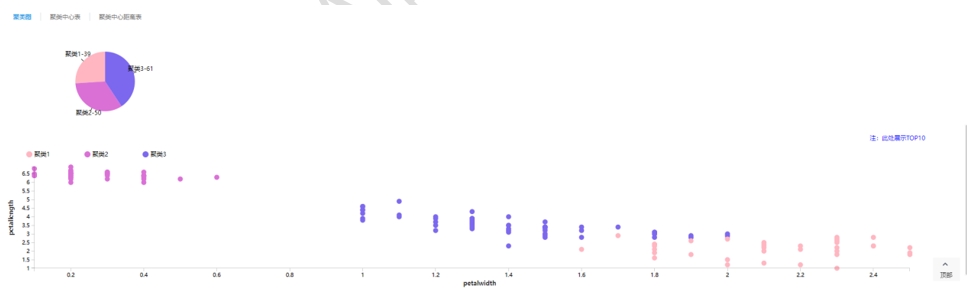


 陜公網(wǎng)安備 61019002000171號
陜公網(wǎng)安備 61019002000171號



